Since the Coskata announcement that they were going to be able to produce ethanol for “under US $1.00 a gallon anywhere in the world” – documented here – I have gotten a number of requests for comments on the technology. After all, GM is on board! GM can’t be wrong, can they? Vinod Khosla’s enthusiasm couldn’t be misplaced either, could it? After crunching the numbers, my conclusion is that not only is this not the ‘slam dunk’ that is being projected, you probably have a better chance of hitting a blindfolded shot from mid-court than Coskata has of producing cost-competitive ethanol.
What leads me to this conclusion? Earlier today I provided some extensive analysis for someone, so I thought I would share it. I am naturally skeptical any time a company comes on the scene and claims – with no operating experience – they can do what Coskata claims (which is also something nobody else has been able to demonstrate). But I also believe in analyzing claims to the greatest extent possible to see if there is anything there. Sometimes this analysis involves reading through patents. Sometimes it involves crunching publicly available information. That’s what I will do in this case.
The source of the numbers is the following article, but is also available elsewhere:
Coskata Picks Pennsylvania for Pilot Plant
There are several pieces of data that are important to note:
Earlier this month, the company told Greentech Media that it already had begun building the 40,000-gallon-per-year plant…
Coskata said the project will cost $25 million, and will be located at the site of a pilot-plant gasifier owned and operated by Westinghouse Plasma Corp., a wholly owned subsidiary of Alter Nrg Corp.
They are building a 40,000 gallon per year pilot plant, which is about 2.6 barrels of ethanol a day. (The fact that they don’t even have an operating pilot plant should tell even the most optimistic supporter that they have little basis for their claims of producing ethanol for less than $1/gal).
Note that the site already has a gasifier, which is one of the most expensive pieces of kit in a gasification plant. Yet the cost is still $25 million – for something that will produce less than 3 barrels a day. Now, take a good look at the graphic below:
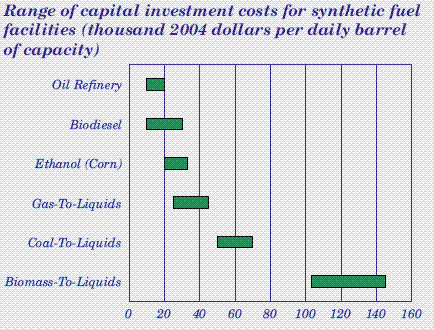
Source: EIA Annual Energy Outlook 2006
Note that the capital costs for a corn ethanol plant are around $25,000 per daily barrel of production. (Caveats are that the graphic is for full-sized plants, and the numbers are a couple of years old). How does this compare to the Coskata announcement? If we look at the 2.6 barrels a day they are planning to produce – and the $25 million price tag – we find that the capital cost per daily barrel is $9.6 million per daily barrel. That is almost 400 times the cost of a corn ethanol plant, and 150 times the per daily barrel cost of a recently announced Neste biodiesel plant.
Of course this is pilot scale, but the capital costs would have to go down by a factor of 100 before they could even start to get competitive – and remember they haven’t even charged the gasifier to the project! To put this all into perspective ConocoPhillips built a 400 barrel per day GTL pilot plant (Coskata is also GTL, but the “L” is going to be ethanol instead of diesel) for $75 million. The cost of that facility was $188,000 per daily barrel – and those economics weren’t good enough to justify scaling up to commercial size.
One final thing I would point out is that the selectivity of these processes generally favors methanol over ethanol. They may be able to push the selectivity toward ethanol, but they will almost certainly end up producing mixed alcohols that will have to undergo purification to ethanol.
The technology will either need a drastic redirection or this is a dead end. Even with a drastic redirection, the present cost that is two orders of magnitude too high to be competitive says that over-hyped Coskata is quite a long-shot to make it to commercial production. Of course with large enough subsidies almost anything is possible.
My prediction? I predict that Coskata’s suggestions that they will produce ethanol for less than $1/gal will look ridiculous in hindsight. The next few years will see a record amount of back-pedaling from most of the companies trying to establish a foothold in this space – and overpromising on their technology to do so. There will be the normal litany of excuses – such as ‘the oil companies are suppressing the technology’ – but in the end the chemistry, physics, and most importantly the capital costs and logistical challenges will catch up with them. Yes, excuses will be made, but those who know a little about the technology will know what really happened. It’s going to be TDP all over again.
The American ethanol scene does not look promising. It can survive, if subsidized. Not sure that is good energy policy. RR has pointed out the very dubious economics of US ethanol.
Jatropha, palm oil seem doable. Much higher yields per acre. China is planting millions of hectares both in China and in Indonesia. If they work, expect copycat farms in Thailand, Burma, the whole Southeast Asia world, and India. A bid advantage of jatropha is that the tree-bush remains planted. Unlike corn and suger, the whole field is not (expensively) ripped up every cycle.
Palm oil is already commercially harvested, so look for palm oil output to keep rising.
Still, with the EVs coming along, I am not optimistic for biofuels. The GM Volt, and other cars, means oil demand could decrease every year, for decades.
I am not sure biofuels are useful in a scenario of declining oil demand.
Let the market sort it out.
Like every farm state Senator says, “There are two things I believe in: Free enterprise and ethanol mandates.”
http://www.abs-cbnnews.com/storypage.aspx?StoryId=123894
If I read this story correctly, world biofuel production by 2017 will be about 3.5 mbd — certainly not to be sneezed at, and suggest IEA recent estimates of global suppy over consumption are conservative,
But the US could cut 4 mbd from consumption just by upping our fleet mpg.
Those biofuel figs are interesting though — suggest a glut on oil markets in two years is ocming…..
Benny,
The market is a wonderful mechanism for finding “The Path of Least Resistance” (POLR).
“Free Markets” implies as little regulation, restriction, and oversight as possible. (Which generally means the creation of as many Externalities as possible)
Which is like using a chainsaw while blindfolded. (i.e. Letting that POLR run wild.)
Clearly, that can lead to devastating results. (Mortgage Crisis, Deforestation, Global Food Shortages, and Water Disputes)
That said, I’m all for “Open Competitive Markets”
Where as I’d say “Free Markets” are merely a libertarian pipedream that only works on paper.
Grey Falcon: Say hello to Mr. Maltese.
Yea, I agree agree that externalities have to be built into the price mechanism, usually through taxes, sometimes through regulation or subsidies.
Still, everytime you open up the political process to decide taxes, regulation and subsidy, you usually get corruption, legal or illegal.
Anyway, I am a fan of a national $3 a gallon gasoline tax, to end roadway subsidies. Such a tax would likely result in decreasing oil consumption in the U.S. for years on end, maybe decades.
But Grey Falcon, you should consider this; If you say an economy should rely primarily on regulation, who then are the regulators? And (given human nature) how long until that regulatory power was badly abused?
I have to say, the most inventive economy still seems to be the U.S. I will also say that Europe is a mile ahead of us in adapting to higher fossil prices.
Well generally, when I say that.
My main concern is with health and safety externalities. i.e. Including the cost of damages.
(Similar to the concept of “Negative Rights”)
http://en.wikipedia.org/wiki/Negative_rights
Now whether the revenues on that externality get spent on the proverbial lifetime supply of scotch and hookers, I don’t really care.
The key is that damaging approaches aren’t made to be artificially cheap. Allowing for the non/less damaging approaches to compete.
Which is the heart of what that study Robert was mentioning the other day was about.
http://i-r-squared.blogspot.com/2008/08/taxes-versus-subsidies.html
I like the work being done with genetically modified yeast. Who wants ethanol,when you can have 100 octane gasoline,or even pure crude oil? The stuff can be tailored to break down anything containing sugar…into any kind of fuel you like. That’s the future for biofuels imo.
This is Wes Bolsen, CMO & Vice President of Coskata. I am really sorry that we were not able to talk before you posted this. I will always try to make myself available.
The division you did above was performed properly, you just didn't have complete information. The ~$25 million project that Coskata is doing in Pennsylvania includes operating costs for approximately a year, capital for improvements to the Westinghouse site before we even get there, and other expenses not incurred on other plants. Either way, I agree with you, commercial demonstrations, even if the Capex were as low as $10 Million for Coskata’s portion is expensive. In fact, that is why we would never want to build a 1 or 2 Million gallon plant, or anything like this for making ethanol.
If you want the approximate capital cost for Coskata's 100 Million gallon per year facility, it is approximately $400 million or $4 per gallon of installed cost. This is the engineering design that has been signed off by a major US engineering firm based on 2008 vendor quoted materials and process flow diagrams. The production cost is still looking to be less than $1/gallon, which is confirmed more and more every day that our pilot facility outside of Chicago runs. The Pennsylvania facility you are talking about is simply the final step in Coskata’s rapid commercialization.
Hopefully this additional information is helpful to you and the readers of the blog. Like I said, I am always willing to talk through our numbers, our strategy, and how Coskata is working to commercialize the technology. Feel free to contact me any time.
Sincerely,
Wes Bolsen
CMO & Vice President
wbolsen@coskta.com
630-657-5800
One of the questions that come to mind about Coskata for me is why they chose plasma gasification. Traditionally plasma gasification has been used for waste and negative value feedstocks as the plasma process is energy intensive (and also uses higher value energy form of electricity). From Alternrg and Westinghouse’s website, their previous projects all seem to fit this mold.
It seems very inefficient to me that they are using plasma to gasify biomass. Perhaps they get better conversion results from plasma? I’m not sure whether they need an ASU for the Coskata implementation.
Perhaps because Alternrg’s plasma process was the most inexpensive with the longest track record, as other processes are either unproven or much larger scale and expensive for their application.
Wouldn’t $4/gallon still put you off on the far right of that chart ($168/bbl)?
Seems like they’d make that $4 per gallon in capital costs back in 2 or 3 years. Hopefully,Robert will talk to the guy and square us away. I’m impressed that he’d take the time to respond to a blog post.
Thanks for dropping by and commenting Wes!
If you want the approximate capital cost for Coskata’s 100 Million gallon per year facility, it is approximately $400 million or $4 per gallon of installed cost.
Why do the ethanol producers always quote their numbers in gal and gal/year? Anything to do with numbers getting obviously tiny when quoted in petroleum quantities (bbl/d)?
100 Million gallon per year = ~6,500 bbl/d. At $400 million that would be ~$61,000 per daily barrel. Impressive stuff – bang in the middle of caol-to-liquids on the picture. All hail, if you can pull that off.
GM can’t be wrong, can they?
LOL! Just like Bill Gates could do no wrong, untill he invested in Pacific Ethanol. And the current GM is no Bill Gates.
Thanks to Wes for coming onboard and giving your numbers.
Optimist, the nice thing about gpy is it makes mental math easy. For large plants you can use 10%/year as a crude rule of thumb for cost of capital, depreciation and O&M. So $4/gpy in upfront cost comes out to $0.40/gallon. Add feedstock, which in Coskata's case should be cheap, and it's not hard to see why they claim $1/gal. In theory, at least.
Refineries and ethanol plants cost much less upfront, but their feedstocks cost $2-3/gallon.
Speaking of miracle companies, Changing World Technologies of Discover magazine "Anything into Oil" fame recently filed for their IPO. After many years they still can't get their first plant to run right. This plant was supposed to produce 9 million gpy. They did 0.9m gallons in 2007, half of the 2006 output. They ran at a 1.5m gpy rate in the first quarter of this year. CWT has burned through a cool $100m since startup and still burns $15-20m each year. Product sales remain below $1m per year.
Maury-
Shell Oil says they can make gasoline from biomass too. I hope it works. What bothers me is that there is just not that many calories in biomass. You could burn biomass and turn steam turbines.
I don’t know much at all about biomass Benny. I’m pinning my hopes on modified ethanol. The backyard still will make one hell of a comeback when folks can brew high octane gasoline.
CHEMICAL ENGINEERS AT California Institute of Technology (Caltech), US, have genetically-modified yeast to produce a broad range of naturally- and non-naturally-occurring benzylisoquinoline alkyloid (BIA) molecules, including antibiotics, nicotine, morphine, and anti-plaque toothpaste additives.
http://tinyurl.com/62sv7c
It’s a brave new world out there…
Speaking of miracle companies, Changing World Technologies of Discover magazine “Anything into Oil” fame recently filed for their IPO. After many years they still can’t get their first plant to run right. This plant was supposed to produce 9 million gpy. They did 0.9m gallons in 2007, half of the 2006 output. They ran at a 1.5m gpy rate in the first quarter of this year. CWT has burned through a cool $100m since startup and still burns $15-20m each year. Product sales remain below $1m per year.
OOPS! I guess they still haven’t fixed the odor problem. Not sure how much of that is to blame for the inconsistent operation.
And, just to be clear, it’s not “anything into oil” it’s more like “lipids into oil”. Still way more efficient than biodiesel. But if you give the TDP plant a cellulose-based feedstock, you’ll just be producing a sweet-tasting effluent…
There’s still an odor lawsuit but gov’t regulators haven’t come after them since 2006. I think low output is just due to problems with their process.
They claim they can tune the process for all kinds of feedstocks but I agree their chemistry seems a lot more limited than their PR.
The IPO looks like a hail mary. They haven’t shown any ramp at all. Hard to imagine anyone will buy this (though I’m sure some will).
Greyfalcon,
Nothing has caused more environmental destruction or continues to cause more environmental destruction than government action.
Who caused the massive pollution at rocky flats, hanford, and other areas? The US DOE.
Who caused the destruction of many watersheds in the West through dam building? The US bureau of reclamation.
Who 1. drained the everglades, 2. Caused massive loss of wetlands with its flood control projects 3. caused massive changes in habitat salinity with the intracoastal waterway? The US army corp of engineers.
What continued to subsidize the pollution of the everglades by making sugar production in Florida profitable? US government sugar tariffs.
Who caused massive habitat destruction to through biofuel mandates? The US EPA (with a big assist from EU environmental regulations).
Who is responsible for the more habitat destruction then any other entity? The US department of agricultural with its plow fence row to fence row philosophy.
Which countries had the greatest amounts of environmental destruction? The wholly government owned, free market banned, countries of the soviet union and china.
A little on the ground experience and historical knowledge makes your statement below laughably ignorant.
“Free Markets” implies as little regulation, restriction, and oversight as possible. (Which generally means the creation of as many Externalities as possible)
Nothing causes more externalities than government action. They have the point of the gun to make it happen and the taxpayers to fund it.
The environment would be in much better shape if “environmentalists” like yourself focusing your efforts where they would do the most good, working to stop government driven environmental destruction.
TJIT
Doggy,
If you want it straight from the horse’s mouth: These papers used to be available on CWT’s site, wonder why they removed them? The Adams paper gives the best explanation of their chemistry, plus it mentions that a lot of the protein feedstock ends up as amino acids in the effluent, I mean organic fertilizer. The other papers apparently assumed the nitrogen would all come out as ammonium sulfate.
Their mass and energy balances are also quite inaccurate (anyone with a sharp pencil can figure that out), and the ludicrous claim of 85% efficiency is still there in the IPO. Perhaps we should allert the SEC…